
온프레미스 환경에서 Elasticsearch 클러스터를 운영하다 보면
서비스 규모가 커질수록 수집되는 로그는 기하급수적으로 늘어나고, 그에 따라 클러스터도 점점 복잡해집니다.
클러스터가 커질수록 상면 공간과 관리 부담이 함께 늘어나면서
효율적인 구성이 필요하다는 사실을 체감하게 되었습니다.

Elasticsearch 운영 패턴과 Hot–Warm 아키텍처
Elasticsearch 클러스터는 크게 마스터 노드와 데이터 노드로 나눌 수 있죠.
마스터 노드는 클러스터 상태를 관리하고, 샤드 배치나 노드 헬스체크 등을 총괄하며
데이터 노드는 실제 인덱스를 저장하고, 검색·집계를 처리하는 핵심 역할을 맡습니다.
운영 패턴을 보면, 로그 검색과 분석은 대부분 최근 데이터에 집중되고 오래된 로그는 단순히 보관의 성격이 강합니다.
모든 로그를 고성능 SSD 노드에 두면, 비용 낭비고
모든 로그를 저사양 스토리지에 두면 성능이 저하되죠.
그래서 Elasticsearch에서는 데이터 성격에 따라 노드를 계층화(Hot, Warm, Cold 등) 해서 운영하는 방식을 권장합니다.
저 역시 이러한 원칙을 따르기 위해 클러스터에 Hot–Warm 아키텍처와 ILM(Index Lifecycle Management) 정책을 도입했습니다.
1. Hot–Warm 아키텍처
Hot–Warm 아키텍처란, 인덱스의 사용 빈도(즉, 디스크 I/O 빈도와 인덱싱·검색 패턴)에 따라
데이터를 구분해 서로 다른 노드에 저장하는 방식입니다.
- Hot 노드 → 최신 데이터, 인덱싱 활발, SSD 기반 고성능 장비 필요
- Warm 노드 → 오래된 데이터, 검색 빈도 낮음, 대용량 HDD 기반으로 비용 절감
이렇게 계층화함으로써 핵심 데이터는 빠르게 처리하고, 잘 쓰이지 않는 데이터는 저비용으로 장기간 보관할 수 있습니다.
Hot 노드에는 빠른 SSD와 충분한 리소스를 제공해 최근 로그를 저장하고,
Warm 노드에는 더 큰 디스크를 장착해 오래된 로그를 옮기도록 구성했습니다.
처음에는 단순히 Hot–Warm 분리만 해도 큰 효과가 있었지만, 실제 운영에서는 추가적인 고민도 많았습니다.
예를 들어 특정 시간대(매일 오전 9시)에 인덱스 생성이 몰려 클러스터 부하가 생기는 문제가 있었는데,
ILM 정책을 일 단위에서 시간 단위로 조정하면서 이를 해소할 수 있었습니다.
2. ILM(Index Lifecycle Management) 정책
ILM이란, 인덱스의 수명 주기를 자동으로 관리하는 Elasticsearch 기능입니다.
운영자가 수동으로 인덱스를 옮기거나 삭제하지 않고, 사전에 정의한 단계별 정책에 따라 자동으로 처리됩니다.
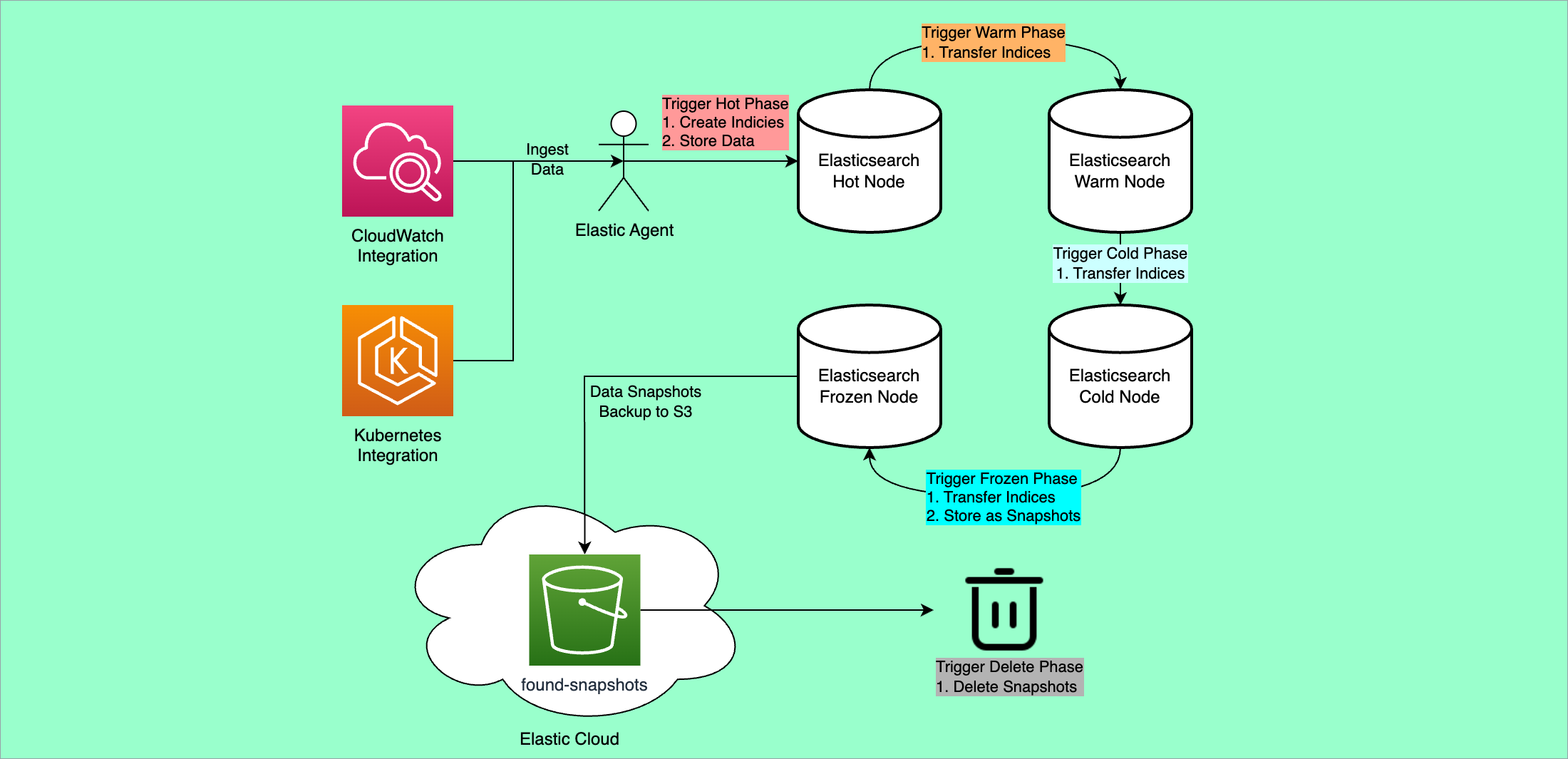
일정 기간이 지난 인덱스는 자동으로 Warm 노드로 이동시키고, 보존 기간이 끝난 인덱스는 삭제되도록 만들었습니다.
이렇게 하면서 일일이 인덱스를 옮기거나 삭제할 필요가 없어졌고,
특정 시간대(예를 들어 오전 9시)마다 인덱스 생성이 몰려 부하가 생기던 문제도 ILM 주기를 조정하면서 완화할 수 있었습니다.
- Hot 단계
- 데이터가 활발히 인덱싱되고 자주 검색되는 시기.
- 고성능 SSD + CPU/메모리 리소스 많은 Hot 노드에 저장.
- Warm 단계
- 더 이상 인덱싱은 거의 없고, 검색 빈도도 줄어든 시기.
- 대용량 HDD 기반 Warm 노드에 저장.
- 필요 시 세그먼트 병합(Force merge)로 저장 공간 절감.
- Cold 단계
- 검색은 드물게 하지만 보관은 필요한 시기.
- 검색 요청 시 디스크에서 직접 읽거나 스냅샷 기반으로 마운트.
- 비용 절감을 위해 리소스는 최소화.
- Frozen 단계 (Elasticsearch 7.12 이후)
- Cold보다 더 드물게 조회되는 데이터.
- 부분 마운트(Partial Mount) 방식으로 스냅샷 저장소에서 필요할 때만 데이터를 읽음.
- 로컬 저장소 사용을 최소화해 비용 절약.
- Delete 단계
- 보존 기한이 끝난 인덱스를 삭제.
덕분에 관리 부담을 크게 줄이고, 장기 보관 정책을 일관되게 적용할 수 있습니다.
무엇보다도 운영자가 수동으로 하던 일이 하나 줄었으니,
클러스터 운영 안정성과 비용 최적화라는 두 가지 목표를 동시에 달성한거죠.
다음 글에서는 이 개념을 실제로 어떻게 적용했는지,
- 노드에 box_type 속성을 지정하는 방법
- 인덱스 라우팅 설정과 샤드 재배치
- ILM 정책을 정의하고 운영하면서 겪었던 시행착오
등을 구체적으로 다뤄보겠습니다.
참고
https://www.elastic.co/docs/manage-data/lifecycle/index-lifecycle-management
https://www.elastic.co/docs/deploy-manage/reference-architectures/hotfrozen-high-availability
https://docs.developer.tech.gov.sg/docs/stackops-documentation/ilm
'ES' 카테고리의 다른 글
| Elasticsearch Hot–Warm 아키텍처 설정 방법, ILM 적용하기 (0) | 2025.09.22 |
|---|---|
| Elasticsearch 데이터는 어떻게 저장되고 검색될까? (0) | 2025.09.19 |
| Elasticsearch 구조와 기본 용어 Cluster, Node, Index, Shard, Segment, Document, Field, Mapping (0) | 2025.09.18 |
| Elasticsearch 역색인이란? Inverted Index (1) | 2025.09.17 |
| Elasticsearch 비밀번호 변경 초기화 하는 법 (0) | 2025.09.17 |




댓글