
이번엔 저번 포스팅에 이어 주문 api XToMany 관계인 Order(주문)과 OrderItem(주문상품)에 대한 이야기다.
XToOne의 경우 fetch join(left outer join)을 하면 성능 최적화가 되는데,
XToMany 관계는 join하면 다(1:다) 측 데이터랑 물려서, 데이터가 뻥튀기(?)된다. 이 뻥튀기라는 말은 이따 코드로 볼 수 있겠지만,
(예를들어 물건 3개를 산 하나의 주문내역을 확인 할 때, 1개의 결과가 나오는게 아니고 3개의 상품이 연결되어 있어서, 결과가 3개가 나와버리는 상황을 말한다.ㅜㅜ) 그래서 고려할게 많아진다.
일단 간단하게 코드를 살펴보자. 일단 처음에 짠 코드는 다음과 같았다.
[Order]
public class Order {
{...}
@OneToMany(mappedBy = "order", cascade = CascadeType.ALL)
private List<OrderItem> orderItems = new ArrayList<>();
{...}
}[OrderItem]
public class OrderItem {
@Id
@GeneratedValue
@Column(name = "order_item_id")
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "order_id")
private Order order;
}
[OrderController]
@GetMapping("/orders")
public List<OrderDto> orders() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return result;
}( findAllByString은 "select o from Order o join o.member m"로 보면 될 것 같다. 저 부분 코드가 좀 더려워서 간단하게만 적어둔다..)
[OrderDto]
@Getter
static class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private List<OrderItemDto> orderItems;
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
orderItems = order.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.collect(toList());
}
}
@Data
static class OrderItemDto {
private String itemName;
private int orderPrice;
private int count;
public OrderItemDto(OrderItem orderItem) {
itemName = orderItem.getProduct().getTitle();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}
여기서 회원1이 상품1, 상품2를 주문하고 / 회원2가 상품1, 상품2를 주문하여 DB에 그 정보가 저장되어 있다.

근데 이러면 저 orders 호출할 때마다 쿼리가.. 6개나 나간다. 이걸 좀 고쳐보자.
findAllByString 대신 findAllWithProduct 이라고 따로 하나 만들어준다.
public List<Order> findAllWithProduct() {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.product p", Order.class)
.getResultList();
}@GetMapping("/orders")
public List<OrderDto> orders() {
List<Order> orders = orderRepository.findAllWithProduct();
for (Order order : orders) {
System.out.println("order ref=" + order + " id=" + order.getId());
}
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return result;
}이렇게 하면 결과가 어떨까?

이게 위에서 말한 데이터 뻥튀기다. 결과가 각각 2개씩 나와버린다.

콘솔에 찍힌 쿼리문을 고대로 H2 디비에 넣어보면 역시 다음처럼 나오는 것을 확인할 수 있다.
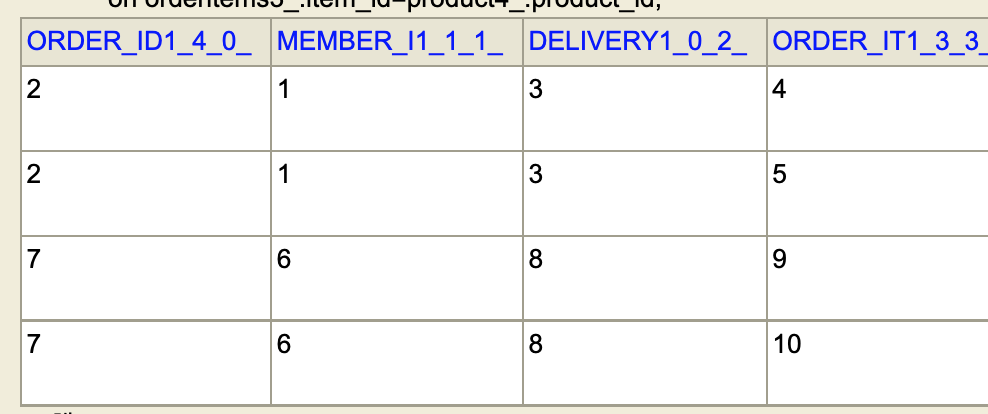
fetch join도 sql 로는 그냥 join 으로 동작하는듯하다. (살짝 다르지만 거의..)
print로 찍어본 주솟값 역시 같은 것을 확인할 수 있다.
이를 distinct 키워드로 해결할 수 있다. 기존 sql의 distinct과는 다르다.
public List<Order> findAllWithProduct() {
return em.createQuery(
"select distinct o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.product p", Order.class)
.getResultList();
}이렇게 하면, 대박적이게도 쿼리가 단 한 번 밖에 안나간다.
그런데 이 fetch join 친구에게 하나 단점이 있는데, 바로 페이징을 할 수 없다는 것이다..
아래 setFirst와 setMax를 넣어서 안되는 것을 확인해보자.
public List<Order> findAllWithProduct() {
return em.createQuery(
"select distinct o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.product p", Order.class)
.setFirstResult(1)
.setMaxResults(10)
.getResultList();
}
WARN 28839 --- [nio-8080-exec-1] o.h.h.internal.ast.QueryTranslatorImpl : HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!메모리에서 페이징 처리를 한다는 경고가 나온다.. 이게 무슨 뜻일까?
예를들어 여기 데이터가 1만개가 있다면, 1만개 전부를 어플리케이션에 올리고 페이징 처리를 하는 것이다.ㅠㅠ
그래서 Out of memory error가 날 가능성이 매우 높다..
왜 이렇게 만들어 졌을까? 하이버네이트는 이걸 왜 이렇게 만들었을까?
이렇게 생각해 볼 수 있겠다. 지금 내가 원하는 order는 2개인데 DB 쿼리에는 데이터가 4개다. 1대 다 조인을 하는 순간, order의 기준 자체가 틀어져 버려서 페이징이 되지 않는다. (order가 아닌 orderItem 기준으로 페이징이 되어버림.) 그래서 1대 다에서 fetch join이 되면 하이버네이트가 경고를 띄우고 이렇게 동작하게끔 한 것 아닌가.. 한다. (김영한 JPA2 강의 참고)
# 컬렉션 fetch join 하면 페이징이 안되는 이유
- 컬렉션을 페치조인(fetch join)하면 일대다(1:N) join이 발생하므로 데이터가 너무 커진다.
- 페이징은 일대다 관계에서 1을 기준으로 페이징을 하는 것이 목적이다. 그런데 데이터가 다(N)를 기준으로 row가 생성된다.
- Order 기준으로 페이징이 되어야 하는데 다(N)측인 OrderItem을 조인하면 OrderItem이 기준이 되어버린다.
그래서 결론은 이 페이징 기술은 데이터가 작을 땐 가능하긴 하지만, 실무에선 상상도 하면 안되는 선택!
+ 또 1대다 fetch join은 1개만 사용할 수 있다. n:n 이 여러개가 되면 n:n:M ... 세상 너무 복잡해짐.
이것을 어떻게 해결해야할지는 다음 포스팅에 정리하겠다.
'🔗 JPA' 카테고리의 다른 글
| [JPA] com.querydsl.core.types.ExpressionException:No constructor found for class - with parameters: (0) | 2022.10.29 |
|---|---|
| OSIV(Open Session in view)이란? 장단점, 써야할지 말아야할지 (0) | 2022.10.21 |
| [JPA] jdbcsqlintegrityconstraintviolationexception null not allowed for column (0) | 2022.10.14 |
| jpa 지연로딩 사용 주의점 (jpa 지연 로딩과 조회 성능 최적화) (1) | 2022.10.13 |
| Setter없이 Entity update (0) | 2022.10.09 |




댓글